
Dataset of Historical Reddit Archive
Overview
The Reddit Archive Dataset was collected and compiled in the month of August 2023. This dataset includes both reddit submissions (Posts) and comments on the interval (2015 - 2022, with plans to stage 2005-2014). The database is hosted on Amazon Web Services and is accessible via AWS Athena and queryable using PrestoSQL. Please e-mail the ASC IT HelpDesk for more information about gaining access via Pennkey SSO.
Getting Started 🤲
Go into aws, access athena, start querying...
Limitations 🤔
Querying is not free, and there is a nominal cost associated with each query. The ASC IT Department sets thresholds for amount of data queried per day, which totals to $5 queried OR 1TB of data scanned. If these limitations are a burden, please do not hesitate to reach out and we can review the usecase for an appropriate solution.
Tips & Tricks 🪄
When querying, it is best to use the partitioned columns in the `WHERE` clause. This will greatly reduce the search space and speed up the query.
Notably, the data on AWS S3 is multi-partitioned along `YEAR` and `MONTH` integer values.
Legality & Terms of Usage 👩⚖️
Please refer to Reddit's Content Policy and the Reddit Data API Terms for more information on the legality of using this data. On consultation with UPenn OIS, it was determined that the data is not sensitive given it's public social media content and therefore can be used for private and well-defined research purposes. The data cannot under any circumstances be used for personal or private gain.
Metadata
Below are schematas for both the `comments` and `submissions` tables. Please click the respective dropdowns to view the SQL table setup & schema
Athena Table Schemas for Comments:
Using sql keyword `Describe` we see the schema for table parquet_reddit_comments
>>> `DESCRIBE parquet_reddit_comments`
created_utc timestamp
author_flair_css_class string
score int
subreddit string
link_id string
subreddit_id string
controversiality int
body string
retrieved_on date
distinguished string
gilded int
id string
parent_id string
edited string
author_flair_text string
author string
day int
year int
month int
# Partition Information
# col_name data_type comment
year int
month int
Athena Table Schemas for Submissions:
Using sql keyword `Describe` we see the schema for table parquet_reddit_submissions
>>> `DESCRIBE parquet_reddit_submissions`
author string
created_utc timestamp
edited string
parent_id string
id string
gilded int
distinguished string
retrieved_on date
title string
controversiality int
subreddit_id string
link_id string
sticked string
subreddit string
ups int
score int
day int
year int
month int
# Partition Information
# col_name data_type comment
year int
month int
Sanity Checking 😵💫
Given that this dataset is quite large and provided from a public academic torrent, there is no way to verify the integrity of the data by the ASC IT Department. The service is provided as-is and provides no guarantees on the accuracy of the data or warranty of fitness.
Public Reference from Reddit
ASC Reference - Sample Query for Unique Values in 2020:
SELECT COUNT(*) as total_rows
FROM ascdata.parquet_reddit_submissions
WHERE year = 2020;
SELECT COUNT(*) as total_rows
FROM ascdata.parquet_reddit_comments
WHERE year = 2020;
Sample Queries 🧑💻
-
The provided query retrieves data from the "parquet_reddit_comment_test" table.
It selects the "created_utc" and "body" columns where the text in the "body" column contains the word "database" (case-insensitive) and the corresponding "year" value is greater than or equal to 2015.
The query returns a maximum of 10 results meeting these criteria.
SELECT "created_utc","body"
FROM "parquet_reddit_comment_test"
WHERE lower(body) LIKE '%database%' AND "year" >= 2015
limit 10;SELECT * FROM "ascdata"."parquet_reddit_submissions"
WHERE author like 'Lotushope'
AND year=2022
and id like '%rxsuj4%'
limit 10;
SELECT * FROM "ascdata"."parquet_reddit_comments"
WHERE year=2022
AND link_id like 't3_wp7j78'
limit 10
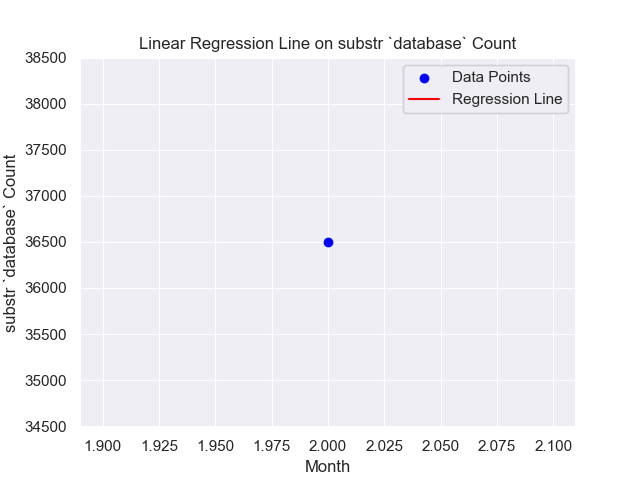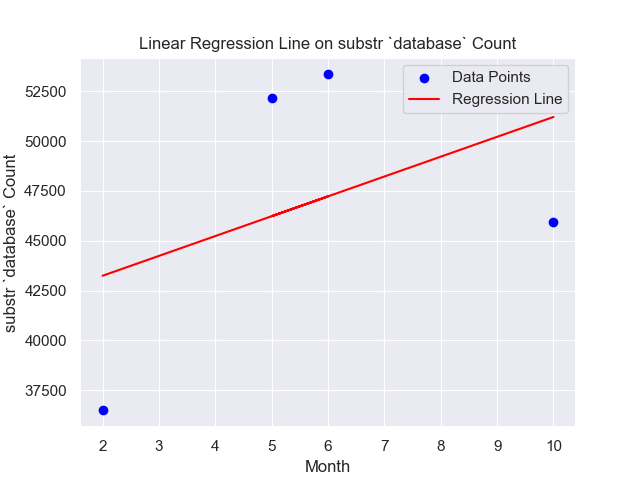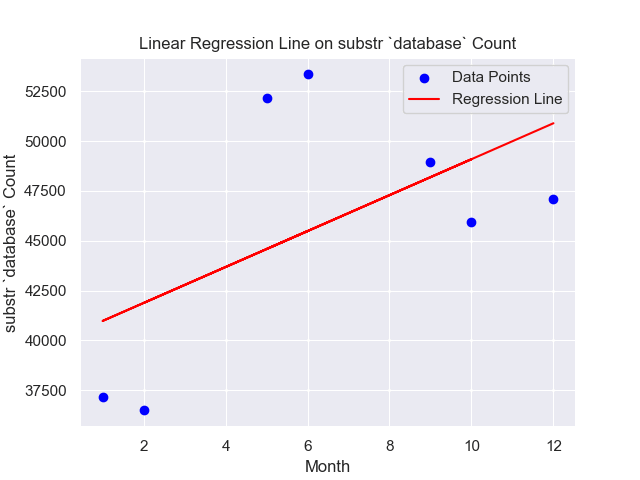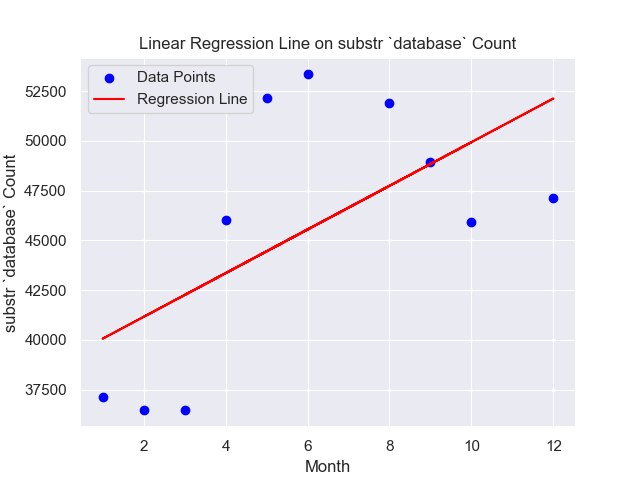
Substring counting across time with substr `database`
Below This SQL query analyzes the "parquet_reddit_comments" table in the "ascdata" database. Focused on the year 2020, it counts comments containing the term "database" (case-insensitive) and groups the count by month. The top 10 months by comment count are displayed.SELECT "month",count(*) AS agg FROM "ascdata"."parquet_reddit_comments"
WHERE lower(body) LIKE '%database%' and "year" = 2020
GROUP BY "month"
limit 10
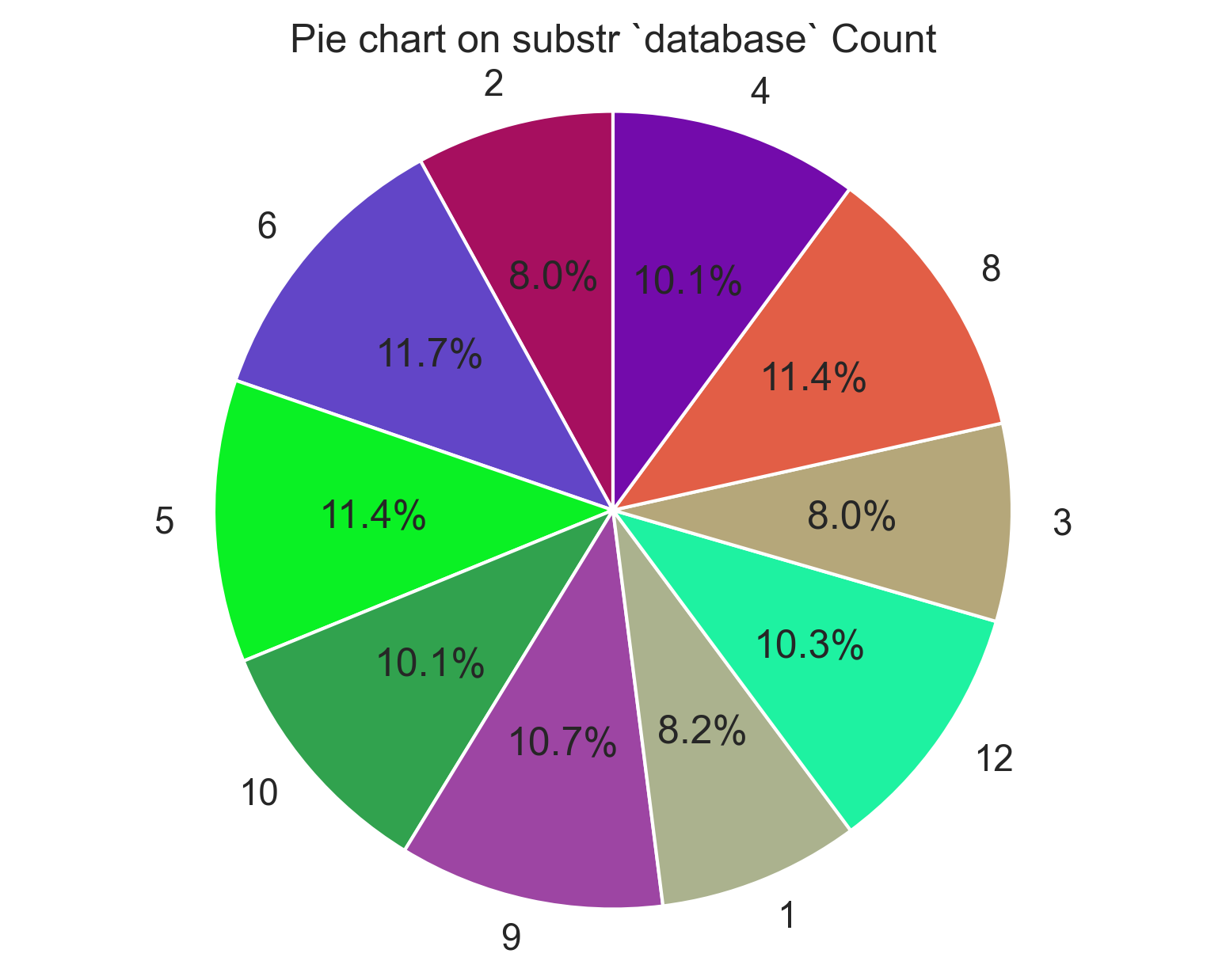
Subbreddit Data Comments
Below This SQL query operates on the "parquet_reddit_comments" table in the "ascdata" database. It targets the year 2020, counting comments for each "subreddit" and labeling the count as "agg." The results are grouped by "subreddit" and sorted in ascending order based on the "agg" count.select "subreddit", count(*) as agg
FROM "ascdata"."parquet_reddit_comments"
where "year" = 2020
group by "subreddit"
order by agg asc
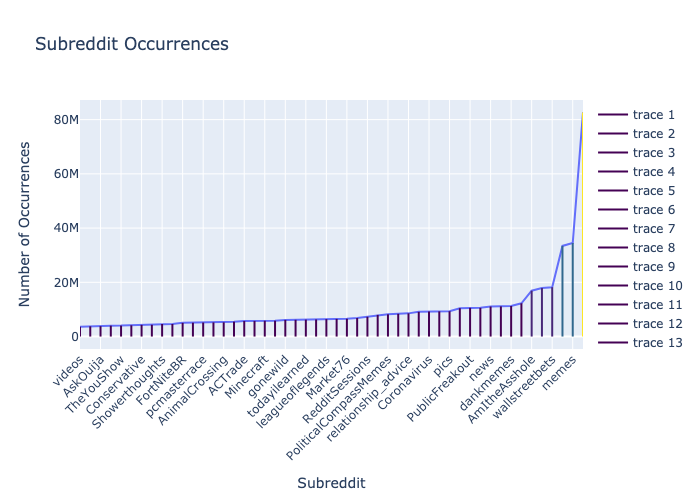
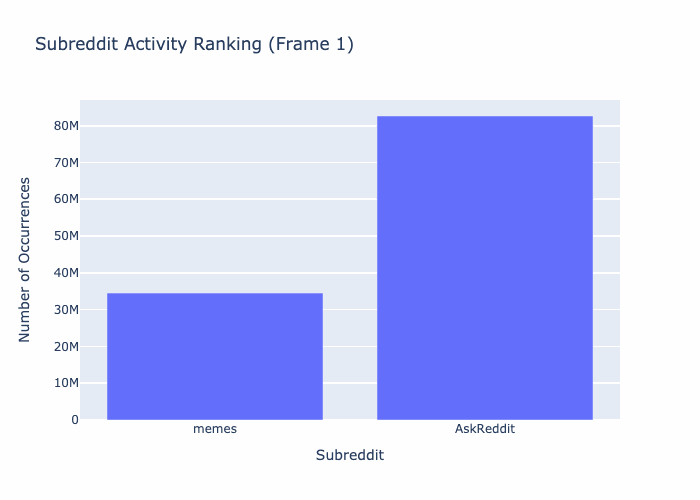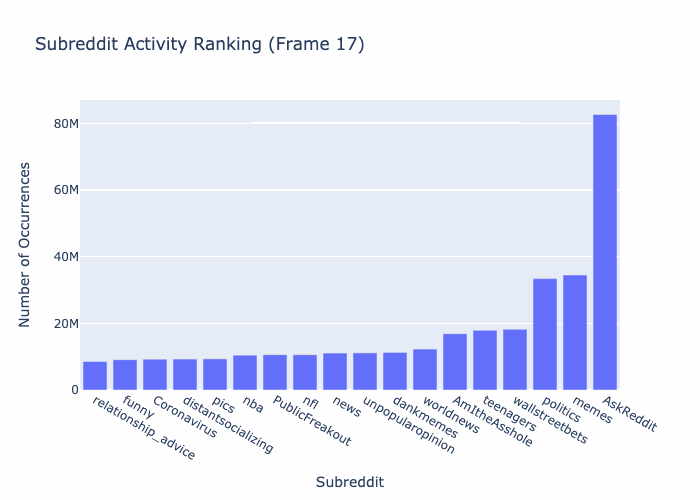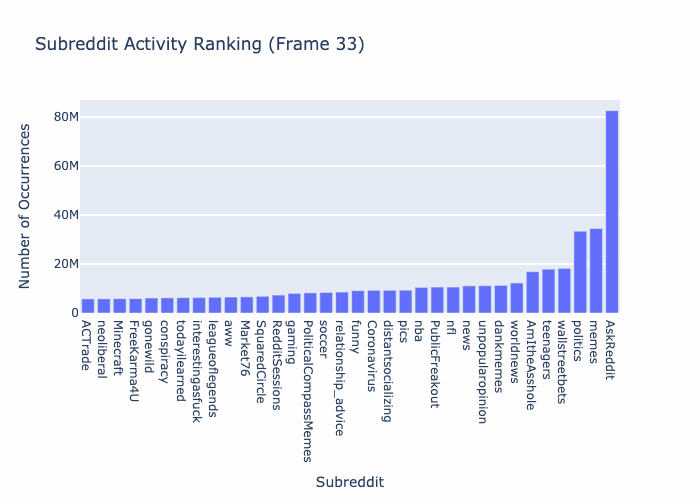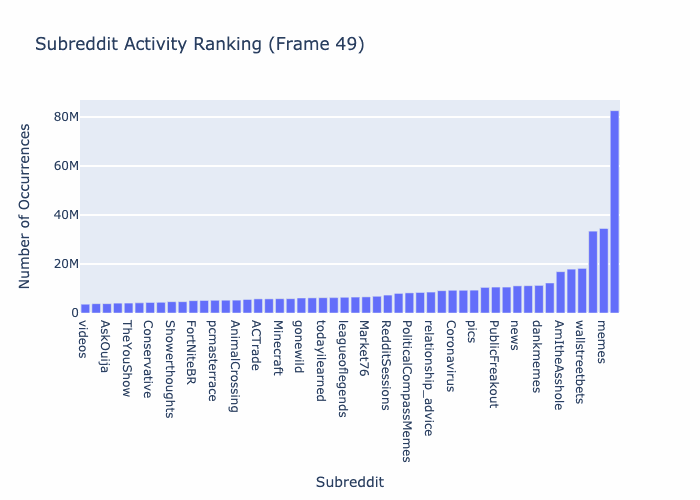
TBD THIS SECTION NEEDS WORK! - 03/21/2024 Etienne P Jacquot